
 木盒主机
木盒主机踩坑实录Hive中select * 没有数据,而select count(*)有数据
发布于 2023-04-11
目录 背景 问题定位 原因1.压缩导致 解决方案 原因2.分区文件location不一致导致 解决方案 原因3.元数据未更新 解决方案 背景 hdfs文件有数据,Hive中select * 没有数据,而select count(*)有数据 问题定位 原因1.压缩导致 表结构未压缩...
阅读(1634)赞 (0)
发布于 2023-04-11
目录 背景 问题定位 原因1.压缩导致 解决方案 原因2.分区文件location不一致导致 解决方案 原因3.元数据未更新 解决方案 背景 hdfs文件有数据,Hive中select * 没有数据,而select count(*)有数据 问题定位 原因1.压缩导致 表结构未压缩...
阅读(1634)赞 (0)
发布于 2023-04-11

目录 一、数据导入 名词解释 基本原理 导入方式 1.Broker Load 2.Spark Load 3.Stream Load 4.Routine Load 5.Insert Into 同步和异步 同步导入 异步导入 通用系统配置 FE 配置 BE 配置 注意事项 二、数据...
阅读(3086)赞 (0)
发布于 2023-04-11
目录 第一部分,自我介绍 第二部分,专业知识细问 第三部分,数据治理 第四部分,开发/代码能力 第五部分,个人性格测试 第一部分,自我介绍 通常面试官会让进行自我介绍,加项目经历介绍(大多数会按简历上的内容逐条细问) 回答的时候尽量根据STAR法则回答,Situation: 事情...
阅读(1283)赞 (0)
发布于 2023-04-11

目录 一、什么是CDP? 二、发展过程 三、CDP的分类 四、CDP的三大特征 五、为什么需要CDP? 六、流程 七、功能 八、应用场景 客户数据平台(Customer Data Platform)是面向业务增长的已消费者为核心的客户全域数据赋能中台。通过汇聚多个触电的数据...
阅读(363)赞 (0)
发布于 2023-04-11

目录 一、什么是索引 二、原理 三、详细内容 四、完整流程示例 1.创建索引语法 2.生成索引 3.查看索引 4.更新索引属性 5.删除索引 二、原理 Hive可以在指定列上建立索引,会产生一张索引表(Hive的一张物理表),里面的字段包括,索引列的值、该值对应的HDFS文件路径...
阅读(864)赞 (0)
发布于 2023-04-11

目录 一、背景 二、概念 三、特性 四、工作原理 五、快速开始 1.数据同步任务模版 kafka to kudu mysql to hive 2.数据同步执行命令 flinkx老版本命令参数: flinkx老版本执行命令: chunjun新版本执行命令:(明显看出命令还是减少...
阅读(636)赞 (0)
发布于 2023-04-11

目录 一、背景 二、流程 三、案例 1.flink sql读取 Kafka 并写入 MySQL source sink insert 2.flinksql读kafka写入kudu source sink insert 四、注意点 1.断点续传 2.实时采集 3.回溯问题 2.实时...
阅读(1032)赞 (0)
发布于 2023-04-11
目录 目录 一、背景 二、代码 1.hive 建表语句 2.datax自定义json 3.查询语句 三、定位问题 四、解决方案 1.load data 2.设置参数 3.文件格式 一、背景 datax同步postgre库表数据到hive表,同步完成后select报错 java.i...
阅读(1317)赞 (0)
发布于 2023-04-10

移动互联网时代,App已经成为了商业银行触达和经营客户的主要阵地。尤其,在疫情爆发之后,银行App作为重要的「无接触」门户,开始扮演越来越重要角色。 此外,随着新一代人工智能的蓬勃发展,智慧金融新模式、新业态不断涌现,有力促进了金融业的转型升级。诸如通过银行与第三方机构的数据共享...
阅读(690)赞 (0)
发布于 2023-04-10
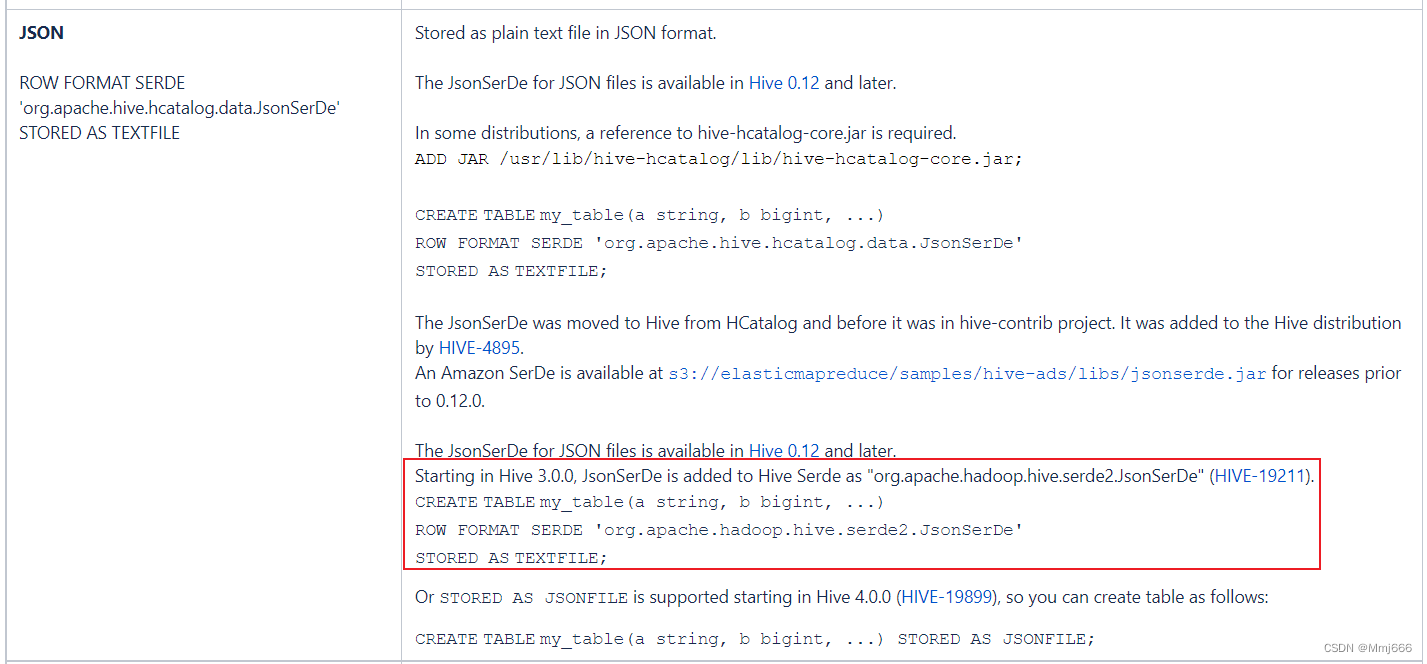
大家好,又见面了,我是你们的朋友全栈君。 数据仓库之ODS层搭建 我们本项目中对数据仓库每层的搭建主要分为两部分,第一部分是确定都有哪些表,第二部分是确定数据装载的方式。 我们在进行ODS层搭建时,需要明确以下几点: 1)ODS层的表结构设计依托于从业务系统同步过来的数据结构。 ...
阅读(2701)赞 (0)
发布于 2023-04-10

知识图谱是下一代可信人工智能领域的关键技术组成之一。围绕知识的归纳抽取、演绎推理等处理与分析过程,诸多关键问题逐步被攻克,大幅推动了机器认知技术的发展。在网络空间安全领域,防御技术的智能化升级也亟需成熟、有效的网络空间安全领域知识图谱(以下简称为安全知识图谱)技术体系,为应对强对...
阅读(338)赞 (0)
发布于 2023-04-04

Hbase简介 HBase是一个开源的非关系型分布式数据库( NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java。 HBase是一个分布式存储系统,具有高可靠性、高性能、面向列、可伸缩(增加或减少硬件的数量)的特点。 高可靠:1.底层文件存储采用的是HD...
阅读(2254)赞 (0)
发布于 2023-04-04
概述 Flink窗口函数是flink的重要特性,而Flink SQL API是Flink批流一体的封装,学习明白本节课,是对Flink学习的很大收益! 窗口函数 窗口函数Flink SQL支持基于无限大窗口的聚合(无需在SQL Query中,显式定义任何窗口)以及对一个特定的窗口...
阅读(1955)赞 (0)
发布于 2023-04-04
flink sql 模式代码demo (Java) (使用flink sql 进行流式处理注意字段的映射) 官方文档类型映射 import com.alibaba.fastjson.JSON; import org.apache.flink.streaming.api.datas...
阅读(917)赞 (0)
发布于 2023-04-04
实例以yarn-per-job为例。 flink提交作业是通过flink run进行提交的,可以从提交脚本中看到启动类即程序的入口是: org.apache.flink.client.cli.CliFrontend 定位到源码中main函数,查看执行逻辑 /** Submits ...
阅读(1793)赞 (0)
发布于 2023-04-04
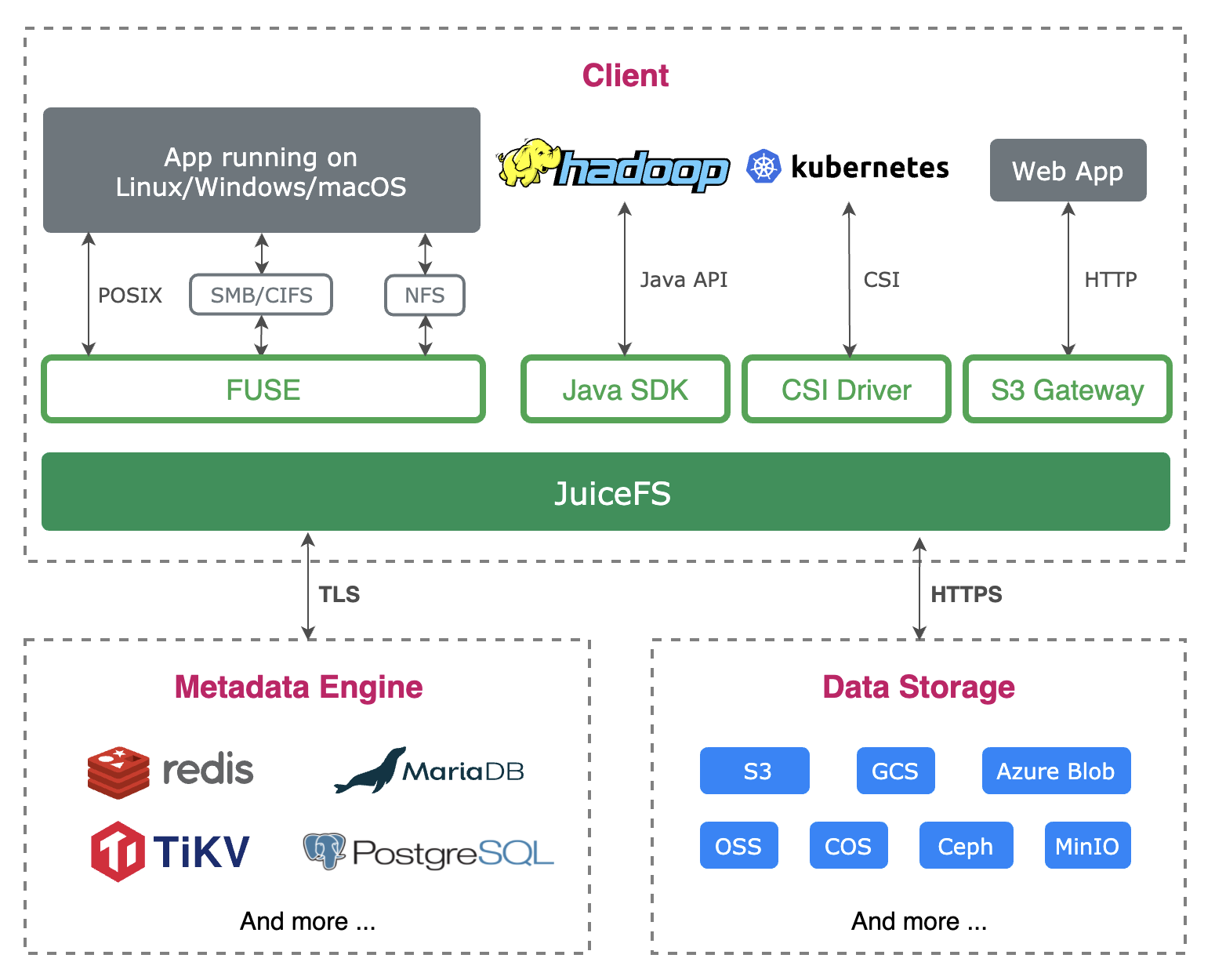
简介 JuiceFS 是一款面向云原生设计的高性能共享文件系统,在 Apache 2.0 开源协议下发布。提供完备的 POSIX 兼容性,可将几乎所有对象存储接入本地作为海量本地磁盘使用,亦可同时在跨平台、跨地区的不同主机上挂载读写。 JuiceFS 采用「数据」与「元数据」分离...
阅读(479)赞 (0)
发布于 2023-04-04

今天分享一篇干货,看完我也获益颇多! 正文 数据治理是企业数据建设必不可少的一个环节。 好的数据治理体系可以盘活整条数据链路,最大化保障企业数据的采集、存储、计算和使用过程的可控和可追溯。 如何构建企业数据治理体系?企业数据治理过程需要注意哪些问题?总体而言,不能一口一个胖子,路...
阅读(2219)赞 (0)
发布于 2023-04-04

大家好,我是才哥。 用户画像是根据用户社会属性、生活习惯和消费行为等信息而抽象出的一个标签化的用户模型。构建用户画像的核心工作即是给用户贴“标签”,而标签是通过对用户信息分析而来的高度精炼的特征标识。 既然用户体验非常重要,那如何去「度量」和「优化整个流程」呢,那就是站在「用户角...
阅读(1367)赞 (0)
发布于 2023-04-04

作者 | 卞东海 @百度 由于大数据时代的发展,知识呈指数级增长,而知识图谱技术又在近年来逐步火热,因此诞生了利用知识图谱技术进行智能创作的新想法。本文将分享基于知识图谱的多模内容创作技术及应用。主要包括以下四大部分: 百度知识图谱概览 百度智能创作全景 多模内容创作技术 落地产...
阅读(413)赞 (0)
发布于 2023-04-04

作者 | 杨旭东 整理 | DataFunTalk 大家好,这里是NewBeeNLP。深度学习时代,某些领域,如计算机视觉、自然语言处理等,因为模型具有很强的特征表达能力,特征工程显得不那么重要了。 但在搜推广领域,特征工程仍然对业务效果具有很大的影响,并且占据了算法工程师很多精...
阅读(467)赞 (0)