
 木盒主机
木盒主机目录
一、背景
二、流程
三、案例
1.flink sql读取 Kafka 并写入 MySQL
source
sink
insert
2.flinksql读kafka写入kudu
source
sink
insert
四、注意点
1.断点续传
2.实时采集
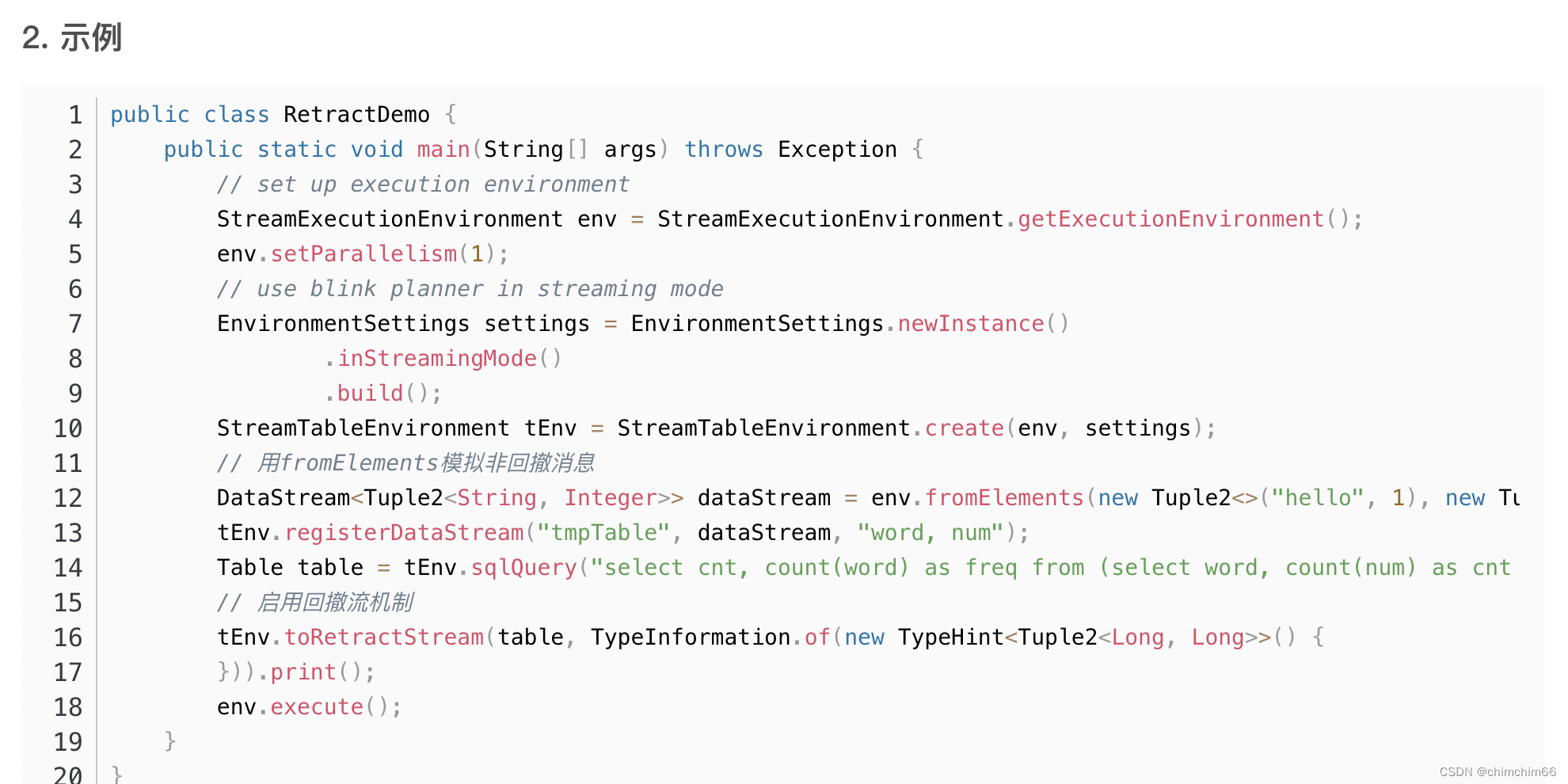
3.回溯问题

2.实时采集
根据数据源的数据是否实时变化可以把数据同步分为离线数据同步和实时数据同步,上面介绍的断点续传就是离线数据同步里的功能,实时采集其实就是实时数据同步,当数据源里的数据发生了增删改操作,同步任务监听到这些变化,将变化的数据实时同步到目标数据源。除了数据实时变化外,实时采集和离线数据同步的另一个区别是:实时采集任务是不会停止的,任务会一直监听数据源是否有变化。
3.回溯问题
例如mysql是事务型数据库,会update,最新的消息发过去,得回撤更新前的消息,update-和update+两条消息,数据都在state里。
简单举个例子,统计男女数量,一开始mysql里是男,然后mysql更新为女了,这时候你接收的kafka,消息都会过来,state里一开始存着男,然后把男回撤,女进来,就要删除男新增女,state一般在rocksdb里,可以设置table.exec.state.ttl 窗口时间。
<code style="margin-left:0">相关参数
val tEnv: TableEnvironment = ...
val configuration = tEnv.getConfig().getConfiguration()
configuration.setString("table.exec.mini-batch.enabled", "true") // 启用
configuration.setString("table.exec.mini-batch.allow-latency", "5 s") // 缓存超时时长
configuration.setString("table.exec.mini-batch.size", "5000") // 缓存大小</code>
ps:因为本人这方面不是很专业,还在学习的阶段,有问题的话大家可以多多指教哈~
未经允许不得转载:木盒主机 » flink sql实战案例
 搬瓦工VPS最新优惠码 搬瓦工最高优惠6.81%优惠码 promo coupon code
搬瓦工VPS最新优惠码 搬瓦工最高优惠6.81%优惠码 promo coupon code  RackNerd:美国VPS 黑五优惠折扣 1核768RAM $10.28/年+神秘盒子 可随机减免金额
RackNerd:美国VPS 黑五优惠折扣 1核768RAM $10.28/年+神秘盒子 可随机减免金额 10G.BIZ【年终钜惠】美国/日本/韩国/香港独立服务器 秒杀仅24起,站群仅需99,三网CN2GIA五折抢购。CERA洛杉矶云服务器仅2.4起
10G.BIZ【年终钜惠】美国/日本/韩国/香港独立服务器 秒杀仅24起,站群仅需99,三网CN2GIA五折抢购。CERA洛杉矶云服务器仅2.4起 2022年RackNerd 美国VPS促销:4TB月流量11.88美元/年,支持支付宝,老优惠$9.89美元/年
2022年RackNerd 美国VPS促销:4TB月流量11.88美元/年,支持支付宝,老优惠$9.89美元/年