
 木盒主机
木盒主机1、搭建集群
Elasticsearch如果做集群的话Master节点至少三台服务器或者三个Master实例加入相同集群,三个Master节点最多只能故障一台Master节点,如果故障两个Master节点,Elasticsearch将无法组成集群.会报错,Kibana也无法启动,因为Kibana无法获取集群中的节点信息。
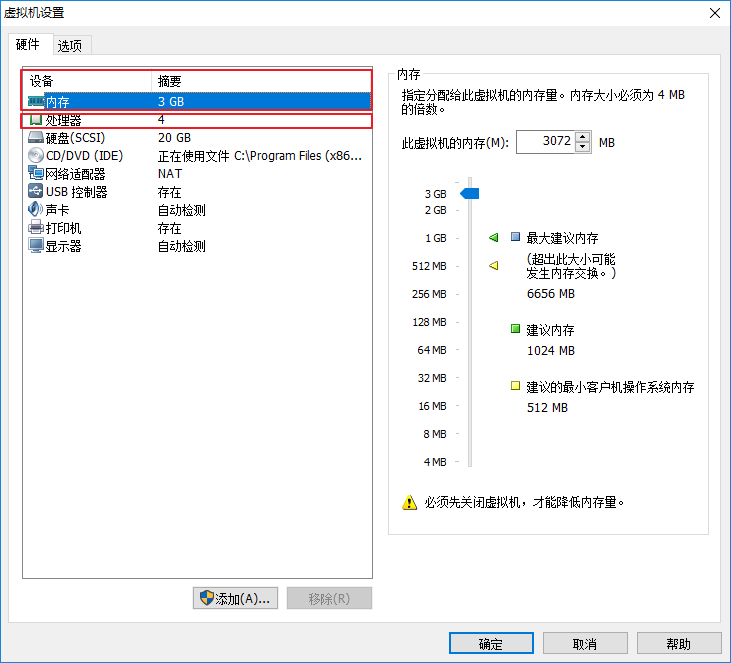
由于,我们使用只有一台虚拟机,所以我们在虚拟机中安装三个ES实例,搭建伪集群,而ES启动比较耗内存,所以先设置虚拟机的内存3G和CPU个数4个
1.1、整体步骤
步骤如下:
- 拷贝opt目录下的elasticsearch-7.4.0安装包3个,分别命名:
elasticsearch-7.4.0-itcast1
elasticsearch-7.4.0-itcast2
elasticsearch-7.4.0-itcast3 - 然后修改elasticsearch.yml文件件。
- 然后启动启动itcast1、itcast2、itcast3三个节点。
- 打开浏览器输⼊:http://192.168.149.135:9200/_cat/health?v ,如果返回的node.total是3,代表集 群搭建成功
在此,需要我们特别注意的是,像本文这样单服务器多节点( 3 个节点)的情况,仅供测试使用,集群环境如下:
cluster name | node name | IP Addr | http端口 / 通信端口 |
itcast-es | itcast1 | 192.168.149.135 | 9201 / 9700 |
itcast-es | itcast2 | 192.168.149.135 | 9202 / 9800 |
itcast-es | itcast3 | 192.168.149.135 | 9203 / 9900 |
1.2、拷贝副本
拷贝opt目录下的elasticsearch-7.4.0安装包3个,打开虚拟机到opt目录
执行 拷贝三份
cd /opt
cp -r elasticsearch-7.4.0 elasticsearch-7.4.0-itcast1
cp -r elasticsearch-7.4.0 elasticsearch-7.4.0-itcast2
cp -r elasticsearch-7.4.0 elasticsearch-7.4.0-itcast3
1.3、修改elasticsearch.yml配置文件
1)、创建日志目录
cd /opt
mkdir logs
mkdir data
# 授权给itheima用户
chown -R itheima:itheima ./logs
chown -R itheima:itheima ./data
chown -R itheima:itheima ./elasticsearch-7.4.0-itcast1
chown -R itheima:itheima ./elasticsearch-7.4.0-itcast2
chown -R itheima:itheima ./elasticsearch-7.4.0-itcast3
打开elasticsearch.yml配置,分别配置下面三个节点的配置文件
vim /opt/elasticsearch-7.4.0-itcast1/config/elasticsearch.yml
vim /opt/elasticsearch-7.4.0-itcast2/config/elasticsearch.yml
vim /opt/elasticsearch-7.4.0-itcast3/config/elasticsearch.yml
2)、下面是elasticsearch-7.4.0-itcast1配置文件
cluster.name: itcast-es
node.name: itcast-1
node.master: true
node.data: true
node.max_local_storage_nodes: 3
network.host: 0.0.0.0
http.port: 9201
transport.tcp.port: 9700
discovery.seed_hosts: [“localhost:9700″,”localhost:9800″,”localhost:9900”]
cluster.initial_master_nodes: [“itcast-1”, “itcast-2″,”itcast-3”]
path.data: /opt/data
path.logs: /opt/logs
参数详解
#集群名称
cluster.name: itcast-es
#节点名称
node.name: itcast-1
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#ip地址
network.host: 0.0.0.0
#端口
http.port: 9201
#内部节点之间沟通端口
transport.tcp.port: 9700
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: [“localhost:9700″,”localhost:9800″,”localhost:9900”]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: [“itcast-1”, “itcast-2″,”itcast-3”]
#数据和存储路径
path.data: /opt/data
path.logs: /opt/logs
3)、下面是elasticsearch-7.4.0-itcast2配置文件
cluster.name: itcast-es
node.name: itcast-2
node.master: true
node.data: true
node.max_local_storage_nodes: 3
network.host: 0.0.0.0
http.port: 9202
transport.tcp.port: 9800
discovery.seed_hosts: [“localhost:9700″,”localhost:9800″,”localhost:9900”]
cluster.initial_master_nodes: [“itcast-1”, “itcast-2″,”itcast-3”]
path.data: /opt/data
path.logs: /opt/logs
4)、下面是elasticsearch-7.4.0-itcast3 配置文件
cluster.name: itcast-es
node.name: itcast-3
node.master: true
node.data: true
node.max_local_storage_nodes: 3
network.host: 0.0.0.0
http.port: 9203
transport.tcp.port: 9900
discovery.seed_hosts: [“localhost:9700″,”localhost:9800″,”localhost:9900”]
cluster.initial_master_nodes: [“itcast-1”, “itcast-2″,”itcast-3”]
path.data: /opt/data
path.logs: /opt/logs
1.4、执行授权
在root用户下执行
chown -R itheima:itheima /opt/elasticsearch-7.4.0-itcast1
chown -R itheima:itheima /opt/elasticsearch-7.4.0-itcast2
chown -R itheima:itheima /opt/elasticsearch-7.4.0-itcast3
如果有的日志文件授权失败,可使用(也是在root下执行)
cd /opt/elasticsearch-7.4.0-itcast1/logs
chown -R itheima:itheima ./*
cd /opt/elasticsearch-7.4.0-itcast2/logs
chown -R itheima:itheima ./*
cd /opt/elasticsearch-7.4.0-itcast3/logs
chown -R itheima:itheima ./*
1.5、启动三个节点
启动之前,设置ES的JVM占用内存参数,防止内存不足错误

vim /opt/elasticsearch-7.4.0-itcast1/bin/elasticsearch

可以发现,ES启动时加载/config/jvm.options文件
vim /opt/elasticsearch-7.4.0-itcast1/config/jvm.options

默认情况下,ES启动JVM最小内存1G,最大内存1G
-xms:最小内存
-xmx:最大内存
修改为256m

启动成功访问节点一:

可以从日志中看到:master not discovered yet。还没有发现主节点
访问集群状态信息 http://192.168.149.135:9201/_cat/health?v 不成功

启动成功访问节点二:
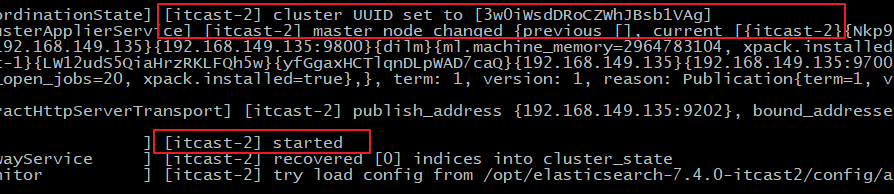
可以从日志中看到:master not discovered yet。还没有发现主节点master node changed.已经选举出主节点itcast-2
访问集群状态信息 http://192.168.149.135:9201/_cat/health?v 成功

健康状况结果解释:
cluster:集群名称
status:集群状态
green:代表健康;
yellow:代表分配了所有主分片,但至少缺少一个副本,此时集群数据仍旧完整;
red: 代表部分主分片不可用,可能已经丢失数据。
node.total:代表在线的节点总数量
node.data:代表在线的数据节点的数量
shards: 存活的分片数量
pri: 存活的主分片数量 正常情况下 shards的数量是pri的两倍。
relo:迁移中的分片数量,正常情况为 0
init: 初始化中的分片数量 正常情况为 0
unassign:未分配的分片 正常情况为 0
pending_tasks:准备中的任务,任务指迁移分片等 正常情况为 0
max_task_wait_time:任务最长等待时间
active_shards_percent:正常分片百分比 正常情况为 100%
启动成功访问节点三
访问集群状态信息 http://192.168.149.135:9201/_cat/health?v 成功

可以看到节点已经变为3个,至此,ES集群已经搭建成功~
2、使用Kibana配置和管理集群
2.1、集群配置
因为之前我们在单机演示的时候也使用到了Kibana,我们先复制出来一个Kibana,然后修改它的集群配置
cd /opt/
cp -r kibana-7.4.0-linux-x86_64 kibana-7.4.0-linux-x86_64-cluster
# 由于 kibana 中文件众多,此处会等待大约1分钟的时间
修改Kibana的集群配置
vim kibana-7.4.0-linux-x86_64-cluster/config/kibana.yml
加入下面的配置
elasticsearch.hosts: [“http://localhost:9201″,”http://localhost:9202″,”http://localhost:9203”]
启动Kibana
sh kibana –allow-root

2.2、管理集群
1、打开Kibana,点开 Stack Monitoring 集群监控
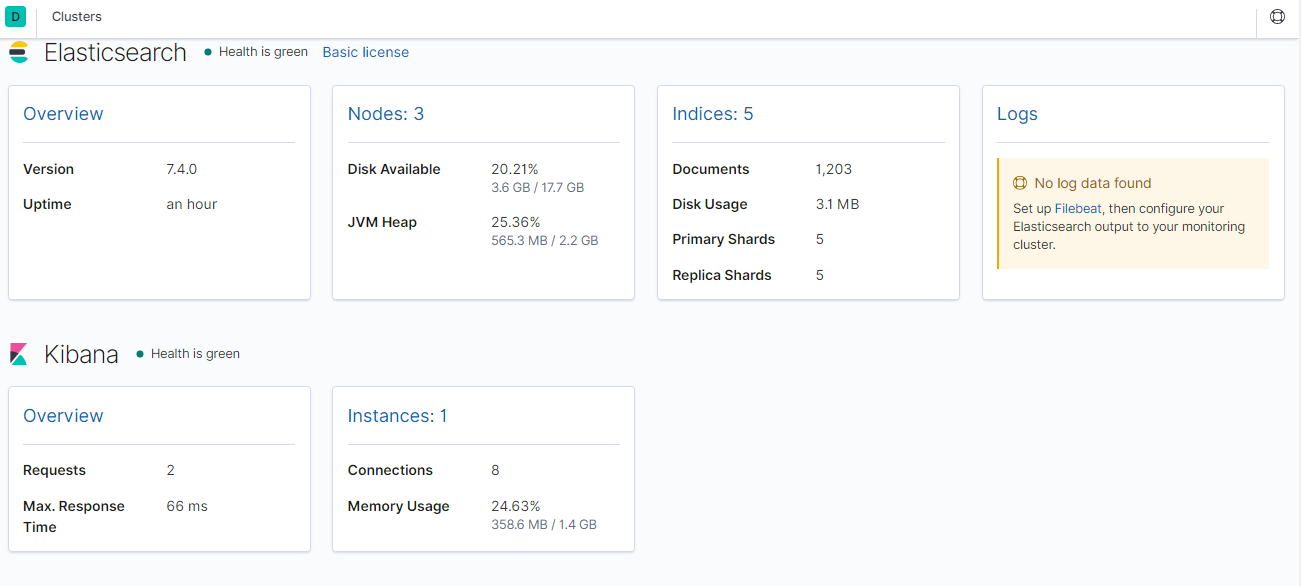
2、点击【Nodes】查看节点详细信息
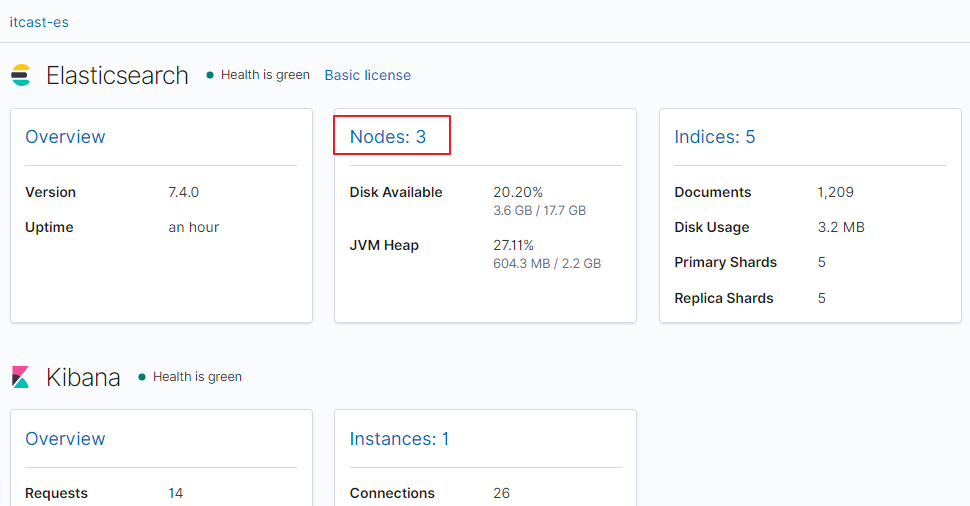
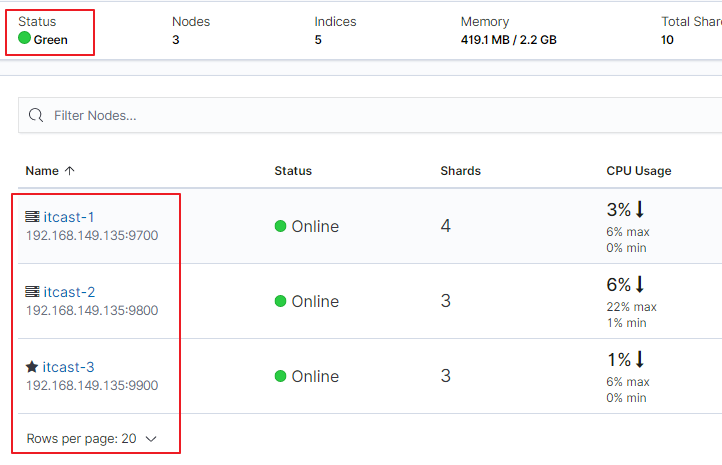
在上图可以看到,第一个红框处显示【Green】,绿色,表示集群处理健康状态
第二个红框是我们集群的三个节点,注意,itcast-3旁边是星星,表示是主节点
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员栈长,转载请注明出处:https://javaforall.cn/182273.html原文链接:https://javaforall.cn
未经允许不得转载:木盒主机 » ElasticSearch 集群搭建[通俗易懂]
 搬瓦工VPS最新优惠码 搬瓦工最高优惠6.81%优惠码 promo coupon code
搬瓦工VPS最新优惠码 搬瓦工最高优惠6.81%优惠码 promo coupon code  RackNerd:美国VPS 黑五优惠折扣 1核768RAM $10.28/年+神秘盒子 可随机减免金额
RackNerd:美国VPS 黑五优惠折扣 1核768RAM $10.28/年+神秘盒子 可随机减免金额 10G.BIZ【年终钜惠】美国/日本/韩国/香港独立服务器 秒杀仅24起,站群仅需99,三网CN2GIA五折抢购。CERA洛杉矶云服务器仅2.4起
10G.BIZ【年终钜惠】美国/日本/韩国/香港独立服务器 秒杀仅24起,站群仅需99,三网CN2GIA五折抢购。CERA洛杉矶云服务器仅2.4起 2022年RackNerd 美国VPS促销:4TB月流量11.88美元/年,支持支付宝,老优惠$9.89美元/年
2022年RackNerd 美国VPS促销:4TB月流量11.88美元/年,支持支付宝,老优惠$9.89美元/年