
 木盒主机
木盒主机大家好,又见面了,我是你们的朋友全栈君。
1. 索引种类
创建数据表& 插入数据
create table user(
id int(10) auto_increment,
name varchar(30),
age tinyint(4),
primary key (id),
index idx_age (age) USING BTREE
)engine=innodb charset=utf8mb4;
insert into user(name,age) values
('张三',30),
('李四',20),
('王五',40),
('刘八',10);聚簇索引
每个 INNODB 表 都会有一个聚簇索引 创建规则如下:
* 如果表设置了主键,则主键就是聚簇索引
* 如果表没有主键,则会默认第一个NOT NULL,且唯一(UNIQUE)的列作为聚簇索引
* 以上都没有,则会默认创建一个隐藏的row_id作为聚簇索引
聚簇索引整体是一个B+树,非叶子节点存放的是键值,叶子节点存放的是行数据,称之为数据页,这就决定了表中的数据也是聚簇索引中的一部分,数据页之间是通过一个双向链表来链接
数据存储结构简图:
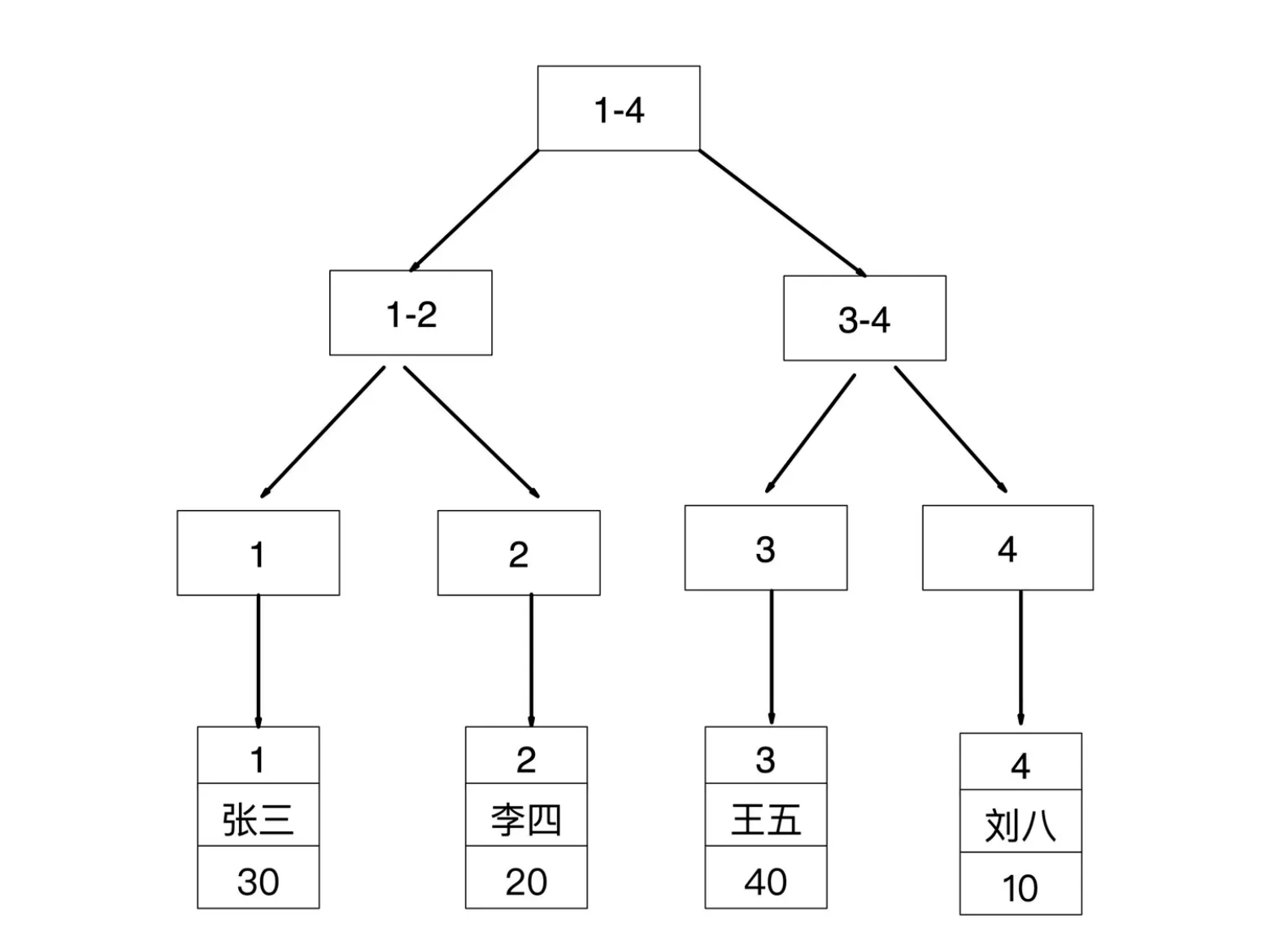
普通索引
普通索引也叫二级索引,辅助索引, 除聚簇索引外的索引,即非聚簇索引。
InnoDB的普通索引叶子节点存储的是主键(聚簇索引)的值,而MyISAM的普通索引存储的是记录指针。
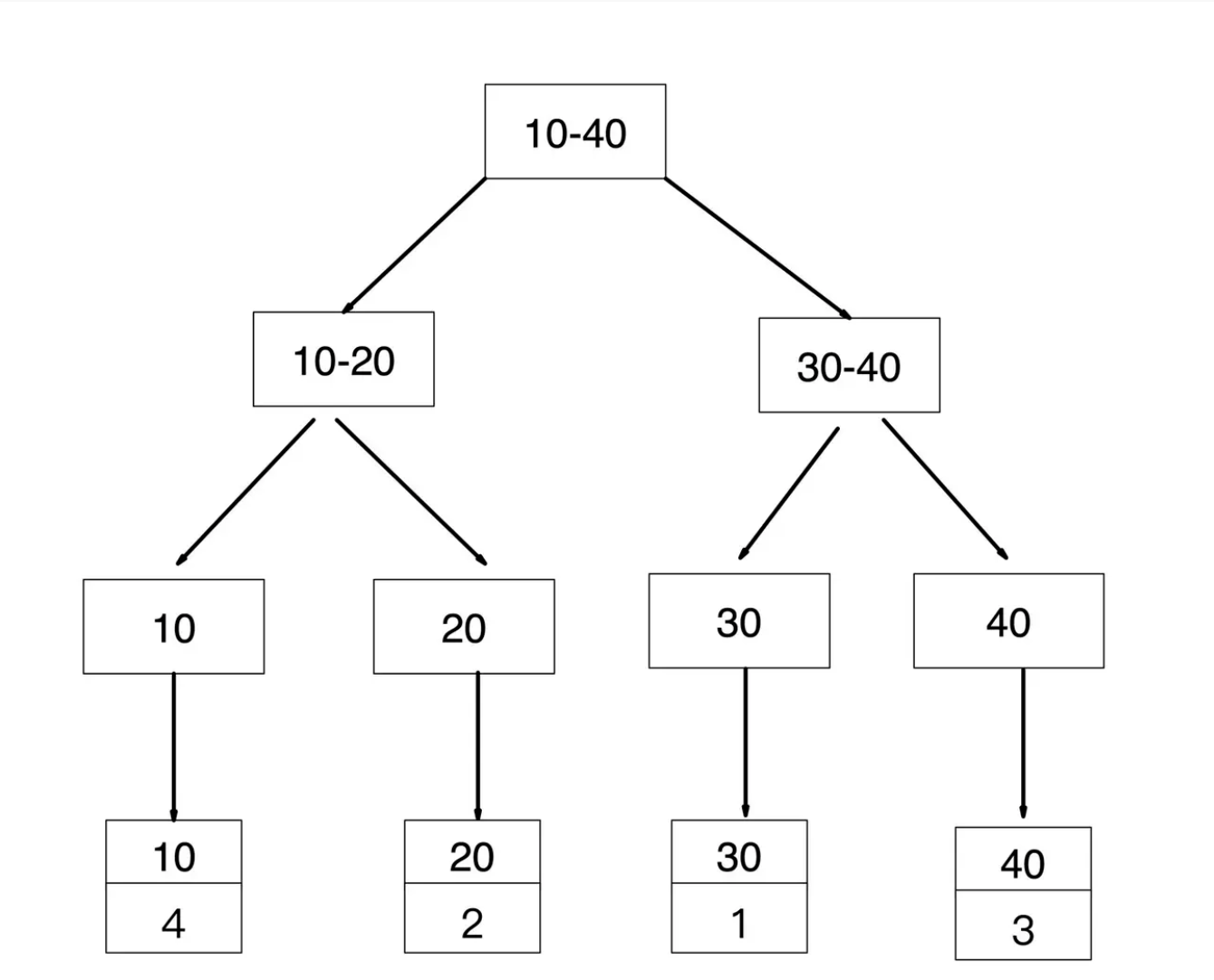
2. 回表查询
执行下面sql查询
select id,name from user where age = 10;分析查询过程, 首先通过普通索引(age) 定位 age = 10 的ID 然后通过聚集索引 查询select 字段返回结果集 , 此过程 需要扫描两次索引B+树,它的性能较扫一遍索引树更低。
3. 索引覆盖
执行下面sql查询
select id,age from user where age = 10;可通过普通索引列(age) 就能获取SQL所需的所有列数据,无需回表,速度更快。
explain 分析:
可通过Extra 是否是Using Index 判断查询是否索引覆盖
如何实现索引覆盖:
将被查询的字段,建立到联合索引里去
哪些场景适合使用索引覆盖来优化SQL
- 全表count查询优化
- 列查询回表优化
- 分页查询
4. 索引下推
在上面数据表的基础上 添加复合索引
index idx_age_name (age,name)
执行下面sql查询,分析查询过程
select id,age from user where name like '张%' and age = 20;Mysql版本 < 5.6
检索复合索引 idx_name_age 查询出所有 name 包含 “张” 的主键ID 然后通过聚簇索引判断出所有符合where子句的数据返回 ,此过程需要回表
Mysql版本 >= 5.6
检索复合索引 idx_name_age 查询所有 name 包含 “张” 的 且age =20 的数据 直接返回结果集, 无需回表
可见 索引下推在非主键索引上的优化,可以有效减少回表的次数,大大提升了查询的效率
explain 分析:

Using Index Condition 使用了索引下推的表现
end!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员栈长,转载请注明出处:https://javaforall.cn/189550.html原文链接:https://javaforall.cn
未经允许不得转载:木盒主机 » MYSQL 回表、索引覆盖、 索引下推[通俗易懂]
 搬瓦工VPS最新优惠码 搬瓦工最高优惠6.81%优惠码 promo coupon code
搬瓦工VPS最新优惠码 搬瓦工最高优惠6.81%优惠码 promo coupon code  RackNerd:美国VPS 黑五优惠折扣 1核768RAM $10.28/年+神秘盒子 可随机减免金额
RackNerd:美国VPS 黑五优惠折扣 1核768RAM $10.28/年+神秘盒子 可随机减免金额 10G.BIZ【年终钜惠】美国/日本/韩国/香港独立服务器 秒杀仅24起,站群仅需99,三网CN2GIA五折抢购。CERA洛杉矶云服务器仅2.4起
10G.BIZ【年终钜惠】美国/日本/韩国/香港独立服务器 秒杀仅24起,站群仅需99,三网CN2GIA五折抢购。CERA洛杉矶云服务器仅2.4起 2022年RackNerd 美国VPS促销:4TB月流量11.88美元/年,支持支付宝,老优惠$9.89美元/年
2022年RackNerd 美国VPS促销:4TB月流量11.88美元/年,支持支付宝,老优惠$9.89美元/年