
 木盒主机
木盒主机背景
缘起:近来想要调研硬件领域过去几年的发展趋势,那些领域取得了较大的进步,哪些领域处于半停滞状态(发展缓慢)?Hackaday作为硬件领域最大的开源平台和社区,致力于发布世界各个角落的精彩Hack项目。因此,我们从Hackaday官网中获取开源项目,通过记录阅读量、点赞数以及学习人数等多个方面的数据,后续结合智能算法实现发展趋势的预测。
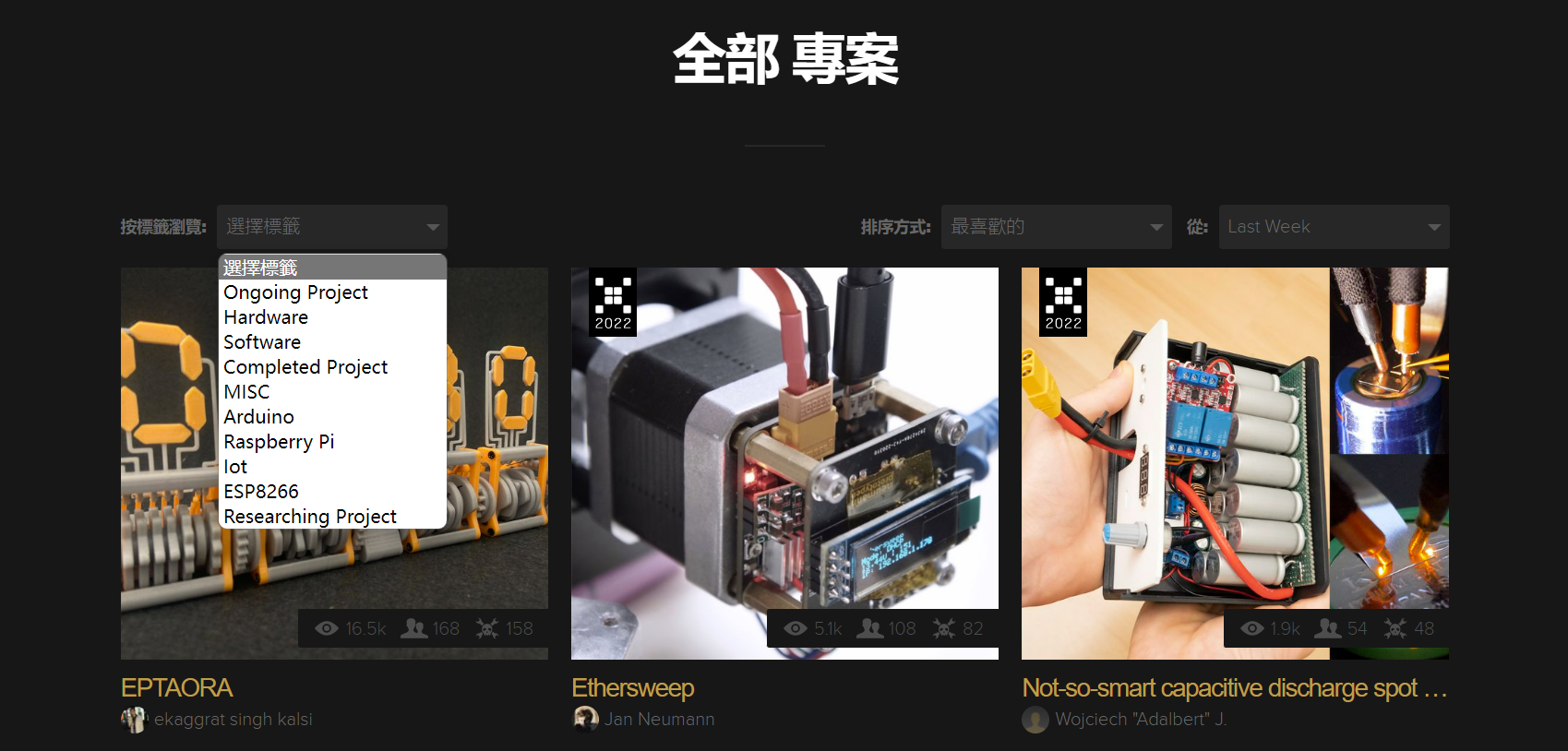
研究目标
项目执行过程中主要存在:1.数据量大;2.网页卡顿问题。因此,为了提高项目推进的速度,我们采用爬虫程序,实现数据的提取及存储。其中,系统采用私有化部署,原生微服务架构,能够极为方便的对系统进行扩展,主要包含的功能模块有:1.数据抓取模块;2.数据存储模块;3.数据分析与数据挖掘模块(异常报警);4.数据可视化模块。
项目执行过程中所用的工具有:1.pycharm集成开发环境;2.PostgreSQL数据库;
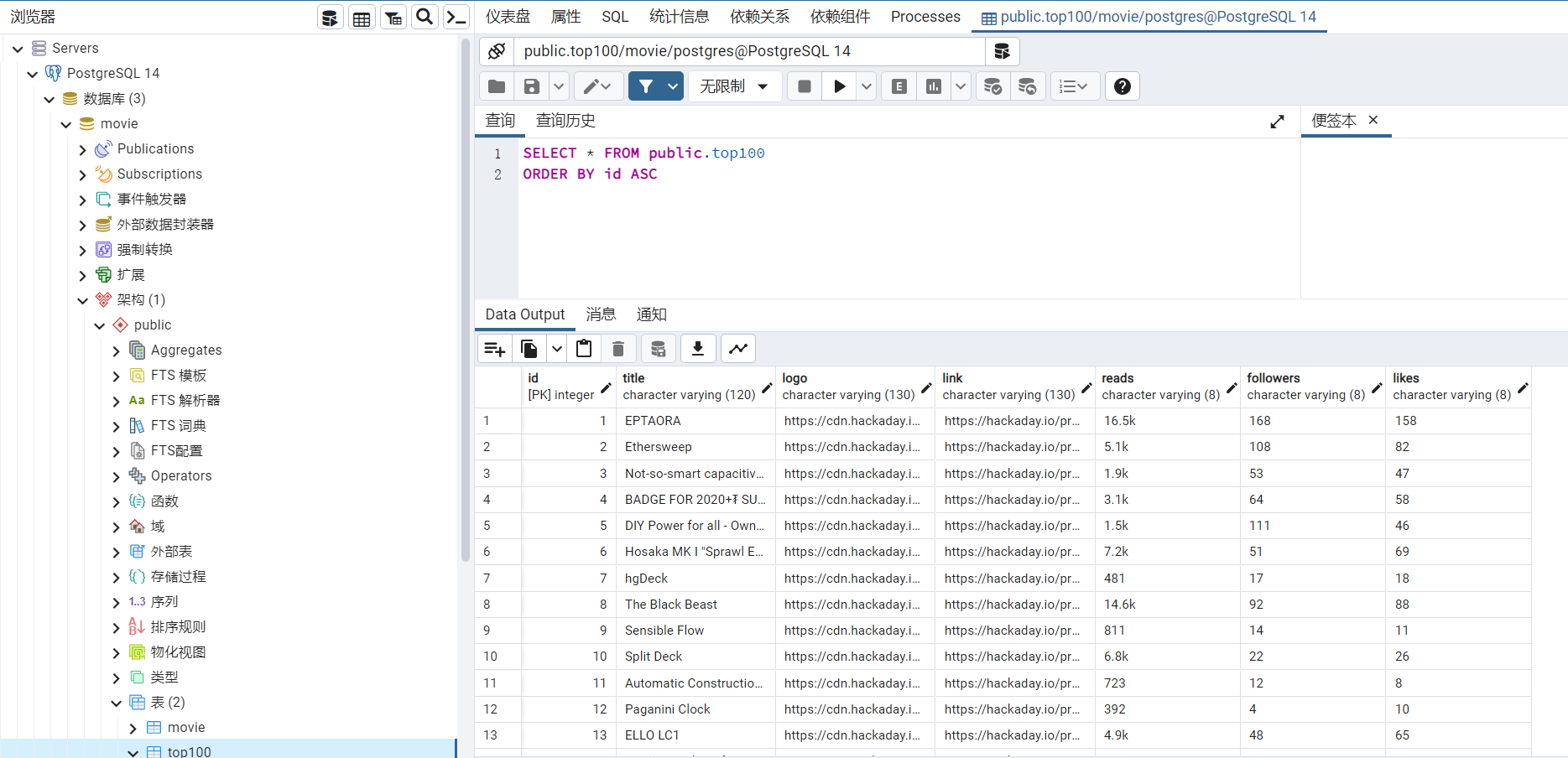
程序源代码
将互联网看成为一张蜘蛛网,那么网络爬虫(Web Spider)就相当于网上的蜘蛛。网络爬虫作为一种很好的数据采集手段,能按照一定规则对互联网上的数据、脚本等信息进行抓取,具体所用的代码如下图所示:
<code style="margin-left:0">import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL
import psycopg2
from bs4 import BeautifulSoup
from lxml import etree
#项目链接
findLink=re.compile(r'<a class="item-link" href="(.*?)"')#?表示.*出现0次到1次
#项目名称
findTiTle=re.compile(r'<a href=.*>(.*?)</a>')
#<a href="/project/187684-eptaora" title="EPTAORA">EPTAORA</a>
def main():
baseurl = "https://hackaday.io/projects?page="
#爬取网页
deleteOperate();
#init_db()
datalist=getData(baseurl)
print(datalist)
def getData(baseurl):#爬取网页
datalist=[]
id=0
for i in range(0,8):#调用获取网页函数10次
url=baseurl+str((i+1)*1)
html=askURL(url)#保存获取到的网页源码
#逐一解析
soup= BeautifulSoup(html, "html.parser")
for item in soup.find_all("div","project-item"): #查找符合要求的字符串,形成列表
data=[] #
item=str(item)
#print(item)
#提取项目链接
link=re.findall(findLink,item)[0]#re库通过正则表达式查找指定字符串的第一个符合条件的
links='https://hackaday.io'+link
data.append(links)
titles=re.findall(findTiTle,item)[0]#片名
titles1 = titles.replace("'", "")
data.append(titles1) #
datalist.append(data)#把处理好的信息放入datalist
id = id + 1
print(data)
saveData(data,id,peopledata)
# print(datalist)
return datalist
def askURL(url):#得到指定的一个网页内容
head = { # 用户代理,表示告诉服务器我们是什么类型的机器、浏览器(告诉浏览器我们可以接收什么水平的信息)
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 52.0.3226.121Safari / 537.36"
}
request=urllib.request.Request(url,headers=head)
html=""
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
if __name__=="__main__":
main()</code>学习记录
网页抓取的核心为:
1.合法、安全;2.系统稳健性:建立容错模式;3.PostgreSQL数据库操作(连接、添加数据、删除等);
遇到的问题
1.网站内容具有特殊字符,如何存储到PostgreSQL数据库;
未经允许不得转载:木盒主机 » 硬件发展趋势调研——数据抓取及存储
 搬瓦工VPS最新优惠码 搬瓦工最高优惠6.81%优惠码 promo coupon code
搬瓦工VPS最新优惠码 搬瓦工最高优惠6.81%优惠码 promo coupon code  RackNerd:美国VPS 黑五优惠折扣 1核768RAM $10.28/年+神秘盒子 可随机减免金额
RackNerd:美国VPS 黑五优惠折扣 1核768RAM $10.28/年+神秘盒子 可随机减免金额 10G.BIZ【年终钜惠】美国/日本/韩国/香港独立服务器 秒杀仅24起,站群仅需99,三网CN2GIA五折抢购。CERA洛杉矶云服务器仅2.4起
10G.BIZ【年终钜惠】美国/日本/韩国/香港独立服务器 秒杀仅24起,站群仅需99,三网CN2GIA五折抢购。CERA洛杉矶云服务器仅2.4起 2022年RackNerd 美国VPS促销:4TB月流量11.88美元/年,支持支付宝,老优惠$9.89美元/年
2022年RackNerd 美国VPS促销:4TB月流量11.88美元/年,支持支付宝,老优惠$9.89美元/年