
 木盒主机
木盒主机大家好,又见面了,我是你们的朋友全栈
上一篇文章我们说到了:大数据开源舆情分析系统-数据采集技术架构浅析
今天跟大家来聊聊我们舆情系统中的数据处理部分是怎么样的工作机制。
简述
舆情系统的数据处理部分我们定义为:数据工厂。
数据工厂,是一套多组件化数据清洗加工及数据存储管理平台,同时能够管理所有的数据库的备份方案。
支持多数据源类型的数据同步实现和数据仓库其他的数据源互通。对接收数据进行解压,对外提供压缩后的数据。
主要用途分为三大块: 1.数据储存,2.数据标记,3.数据挖掘 。
经历了很多版本的迭代升级,期间采用过机器学习、深度学习、tensorflow 和 PaddlePaddle,经历大量的开发测试与项目实战经验。
开源技术栈
- 开发框架:SpringBoot
- 开发语言:Java JEE
- 数据暂存:MySQL
- 数据索引:Redis
- 深度学习:PaddlePaddle
- 数据流水线:Apache Flink
- 自然语言处理:HaNLP & THUCTC
- 数据处理和储存任务发送:Kafka&Zookeeper
- 数据中台:自研 & DataEase
主体流程
- 选择需要处理的数据源,开启(或者关闭)数据处理开关,获取爬虫工厂抓取初加工的数据。
- 在配置界面上对数据处理流程自定义,并且可以看见处理列表和处理详情,以及当前总体的计算状态和计算负载统计。(整套技术方案可以自研,也可以使用为基础,初步评估flink可以满足我们大部分需求)
- 数据处理环节有6种类型:组合汇聚数据源、ETL 网页解析、自然语言处理、标签工场标记、自定义python java反射代码、对附件的处理。
- 每种数据源类型可定义输出不同的数据处理结果和存储目标。
- 对应每一种数据处理结果有每个不同的数据调用接口,接口都是根据数据字段自动生成。管理员用户可操作关闭数据调用开关。
- 用户可以查看每个数据处理结果的数据结果,可以通过筛选、搜索关键词对具体的数据内容查看。
备注:在项目初期应该用最简洁明了的方式对数据处理加工,等到对自身需求有一定深刻认识的时候,再对具体的数据工场的具体功能设计。进过对工商数据,对资讯数据,对招投标数据的输入、输出、处理、调用的各个环节后,会对数据工场具体需求有一个全面的认识。
技术架构
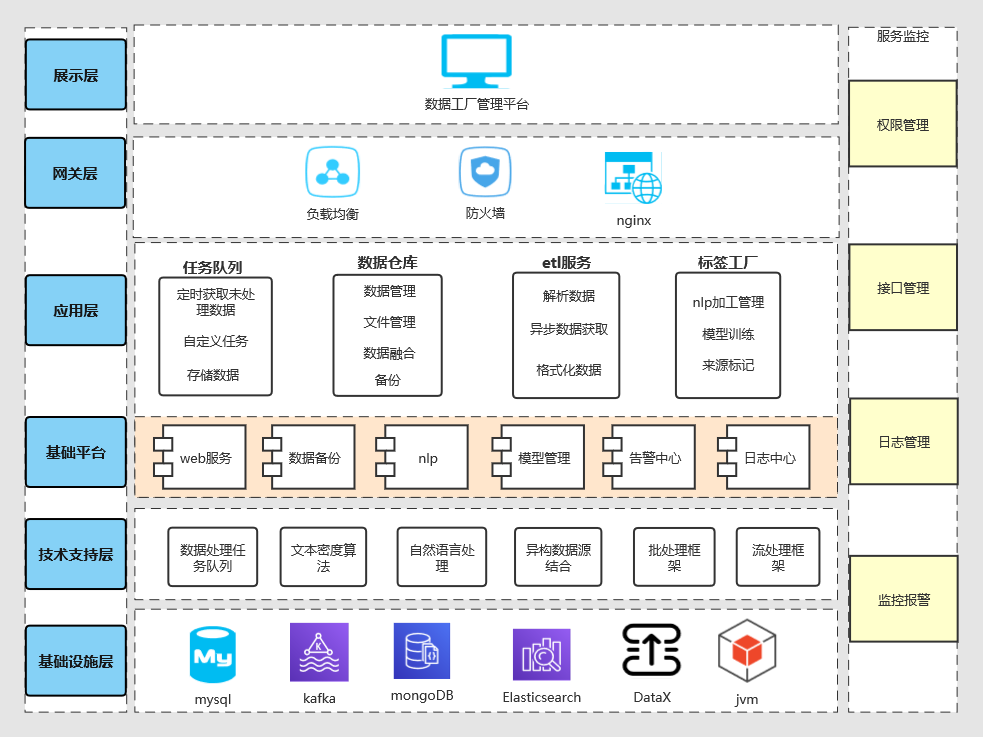
(这是最早期系统架构图)
数据处理流程
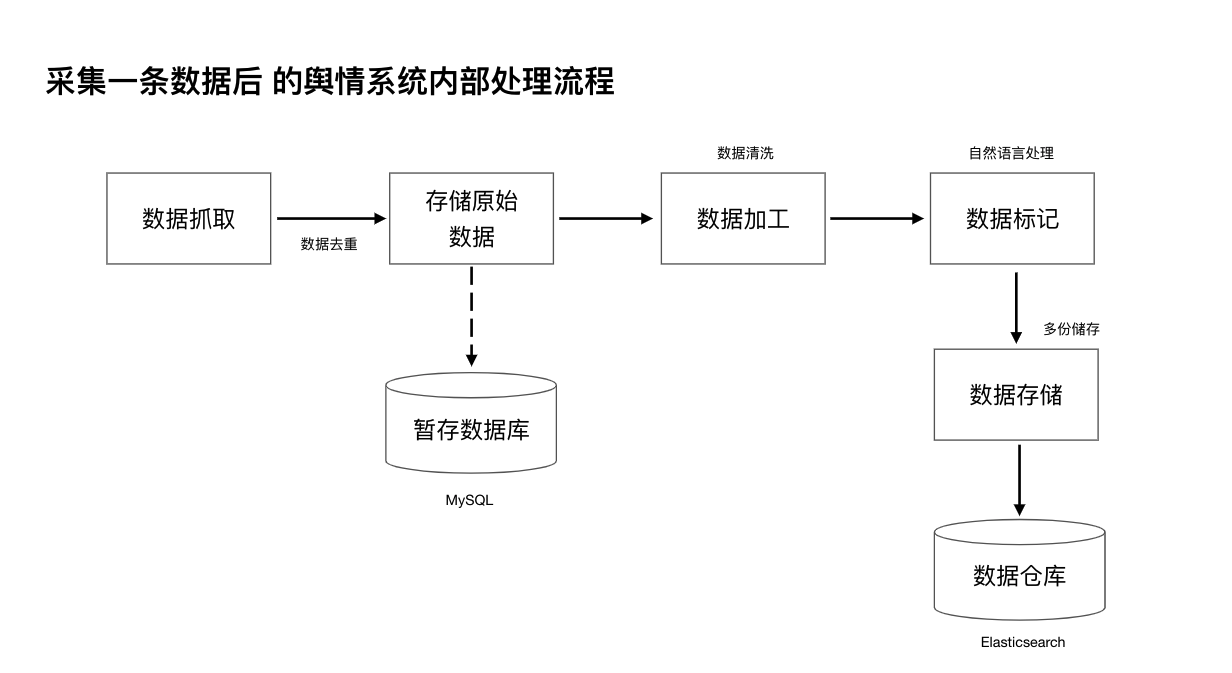
数据总线
我们自研了一套数据总线系统API与Elasticsearch对接,将内部整套数据处理流程完成后,通过低代码化的API接口框架对输出。
数据存储
为了储存海量的数据,同时还能保证系统的性能和运行效率,我们将一条数据储存了多份,用储存空间换取查询时间。
- MySQL
在系统中储存两部分相关的信息内容,系统配置和临时脏数据储存。 - redis
在系统中除了作为系统缓存,还作为站点数据采集的index索引库。 - kafak
由于数据处理的过程比较多,而且数据量很大,因此采用分布式以及异步的方式对海量数据加工处理。 - Elasticsearch
储存加工好的数据、去掉样式的原文信息,以及打上各种标签的数据,储存在分布式搜索中,这样便于用户对数据的检索。 - MongoDB
带样式的文章正文原始网页储存在MongoDB中。 - Clickhouse
将每篇文章指纹及海明距离储存在clickhouse中,以便于对相似度和文章主题聚类的计算。
数据去重
- URL去重
采用了redis集群,让redis发挥天然的key/value魅力,把URL都存储在redis中。 - 内容去重
采用Elasticsearch内部的查询将文章标题一样的内容检索过滤掉。
数据清洗
- 自动提取字段,标题、正文、时间、作者、来源 等。
- 采用自动分类技术对 软文、广告文、敏感文章分类,并且对抓取信源屏蔽。
数据标记
- 内容简介
我们自研了一套自然语言处理的API,我们对此也开放了出来,可以查阅。 - 实体识别
在HaNLP的基础上进行训练和二次开发,在实战的过程中收集数据样本以及对数据样本标注是最痛苦的事情,为此,我们还开发了一款可以辅助人工标记的工具。 - 情感分析
百度飞桨,我们使用了 PaddleHub 深度学习框架并且采用了 Senta模型 ,这个方案上手很简单,在百度飞桨官方网站上有详细内容,这里就不赘述了。 - 高频词分词
采用IK分词框架,在此基础上实现了高频词提取工具及API接口。 - 文本分类
由清华大学自然语言处理实验室推出的 THUCTC(THU Chinese Text Classification) - 相似文章
将文章通过“海明距离”算法生成加密串码存储在clickhouse集群中,通过clickhouse距离查询方法实现,文章相似度聚类。 - 事件分类
自研算法,采用文本分类算法和高频词以及自己开发了一个管理后台。 - 行业分类
自研算法,采用文本分类算法和高频词以及自己开发了一个管理后台。
数据运维
- 数据清理
需要定期对 Elasticsearch、Mongodb 中存储的数据删除,同时还要将Mongodb中的表删除,否则磁盘空间容量不会减少。 - 数据备份
关键性数据采用实时数据备份方案,例如:ES集群和MySQL主从备份,另外,线上实时ES集群我们只保留最近2年的数据。
非关键性数据采用离线数据备份方案,例如:采用datax+Linux脚本定时备份,上传到远程异地备份服务器。
开源舆情系统
项目地址:
https://gitee.com/stonedtx/yuqing
在线体验系统
- 环境地址:http://open-yuqing.stonedt.com/
- 用户名:13900000000
- 密码:stonedt
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员栈长,转载请注明出处:https://javaforall.cn/191359.html原文链接:https://javaforall.cn
未经允许不得转载:木盒主机 » 基于大数据的舆情分析_舆情与大数据
 搬瓦工VPS最新优惠码 搬瓦工最高优惠6.81%优惠码 promo coupon code
搬瓦工VPS最新优惠码 搬瓦工最高优惠6.81%优惠码 promo coupon code  RackNerd:美国VPS 黑五优惠折扣 1核768RAM $10.28/年+神秘盒子 可随机减免金额
RackNerd:美国VPS 黑五优惠折扣 1核768RAM $10.28/年+神秘盒子 可随机减免金额 10G.BIZ【年终钜惠】美国/日本/韩国/香港独立服务器 秒杀仅24起,站群仅需99,三网CN2GIA五折抢购。CERA洛杉矶云服务器仅2.4起
10G.BIZ【年终钜惠】美国/日本/韩国/香港独立服务器 秒杀仅24起,站群仅需99,三网CN2GIA五折抢购。CERA洛杉矶云服务器仅2.4起 2022年RackNerd 美国VPS促销:4TB月流量11.88美元/年,支持支付宝,老优惠$9.89美元/年
2022年RackNerd 美国VPS促销:4TB月流量11.88美元/年,支持支付宝,老优惠$9.89美元/年